How many times we have got the situation where we have to build the logic in your code that checks for the existence of a row, then based on the outcome of that existence check you either perform an INSERT statement (if the row does not exist), or an UPDATE statement (if the row already exists?) with the release of SQL Server 2008 introduced the MERGE statement to make that task a lot easier. In this article I will be discussing how to perform inset, update and delete logic using the MERGE statement.
let’s start MERGE.
How it works:
the MERGE statement basically works as separate insert, update, and delete statements all within the same statement. You have to specify a “Source” record set, a “Target” table, and the join between the two.
You specify the type of data modification that is to occur when the records between the two data are matched or are not matched.
MERGE is very useful, especially when it comes to loading data warehouse tables, which can be very large and require specific actions to be taken when rows are or are not present.
Capabilities of MERGE Statement
the MERGE statement allows you to write code to determine how to compare two tables and then determine if an INSERT, UPDATE, and DELETE operations needs to be performed against one of the tables. The MERGE statement can also use the TOP clause to only perform a specific number of operations.
Like the normal INSERT, UPDATE and DELETE statements the MERGE statement can also output information so you can identify specifically what rows and values where inserted, updated and deleted.
Insert or Update Logic (UPSERT)
give example shows the MERGE statement to Insert or Update records in one table based on the records contained in another table.
These tables are identified to the MERGE statement as a “Source” and a “Target” table. The target is the table that will have records updated or inserted, whereas the source table contains the records that will be used by the MERGE statement to identify the records in the target table that will be updated or inserted.
let me start with creating sample tables.
so we can apply the MERGE logic on the tables.
After creating source and target tables I will use ID column to determine whether or not a row from the Source should update or insert a row in the Target table.
I want to use merge logic to update the Target table anytime there are matching rows between the Source and Target table based on the ID column values.
but based on the ID column if any rows in the source table do not match with the target table rows, then Insert operation will be performed.
in the MERGE statement in the Target table is the table that is referenced right after the MERGE keyword.
the Source table of the MERGE statement is reference right after the USING keyword.
In example I joined these two table based on the tagid column, to determine if a record in order to identify the records to be inserted or updated the ON clause is used to join the records between the Target and Source tables, just like you would do in a normal JOIN operation.
I joined two tables based on the tagid column, to determine if a record in the Target table should be updated or inserted the When clauses are used. The two When clauses in this example have two different criteria.
The first query “When Matched”, and the second query “When Not Matched”.
the “When Matched” option the action to perform when a record in the Source table matches a record in the Target table based on the ON condition.
if the “When Matched” criteria is met then the code will use column information in the matched Source table record to update the matching record in the Target table.
————————————————————————————————————
INSERT In MERGE Statement
————————————————————————————————————
If a row in the Source table does not match to a record in the Target then the “When Not Matched” logic will be used to insert a record into the “Target” table, based on the column information in the “Source” table for the unmatched row.
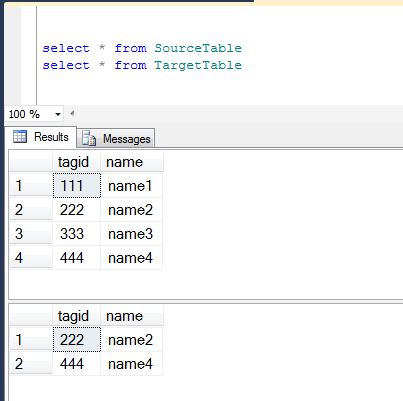
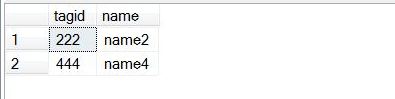
Target Table Before.
Target Table Before MERGE statement execution.
by reviewing the results in above images you can see that the TargetTables for the row with two tagid s of 111, 333 were inserted into Target table because the row with an tagid from SourceTable to TargetTable did not match with Not Matched condition.
————————————————————————————————————
UPDATE In MERGE Statement
————————————————————————————————————
Let’s Work on Update condition from the MERGE Statement.
I am changing the value of tagid 1 from name1 to name11.
The Source Table with updated value.
Let’s run the MERGE Statement again.
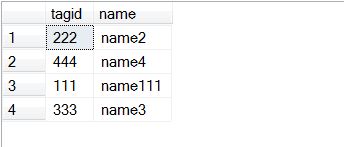
Target Table Before the update condition from MERGE statement.
Target Table Before the update condition from MERGE statement.
by reviewing the result images, you can see that the Target table for the row with an tagid of 111 was updated from name1 to name111. This was accomplished because an tagid column value of 111 met the WHEN MATCHED condition, which caused the UPDATE statement to be executed that used the name column value from the source table to update the target table.
————————————————————————————————————
DELETE In MERGE Statement
————————————————————————————————————
the MERGE statement can perform more just an INSERT and UPDATE against the Target table, it can also perform DELETE operations.
let’s suppose we need to build a process that needs to maintain a table that contains all the records in a source system.
if we are inserting , updating and deleting records in source system, you will have to do the same insert, update and delete in the target from the source.
to explain I will delete one record from SourceTable, and I will execute the MERGE statement to check that MERGE can delete the same record from the TargetTable.
this is the initial values in both Source and Target tables.
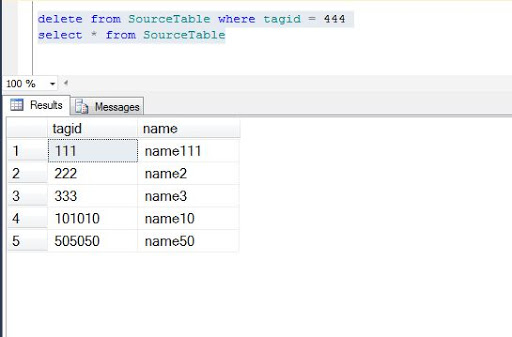
now my first step is to delete record of tagid 444 from SourceTable.
second step is to run runn MERGE Statement, and after execution of MERGE we should not get the record of tagid 444 from TargetTable.
Step1:
Step2:
above image shows the TargetTable without having a tagid 444.
meaning we are successfully able to perform DELETE operation using MERGE.
————————————————————————————————————
OUTPUT Clause In MERGE Statement
————————————————————————————————————
OUTPUT Clause is used in MERGE statement to display information about what values that were updated, inserted or deleted.
I will Insert and Update records in Source table to demonstrate how to use the OUTPUT clause.
above image shows the OUTPUT Clause with MERGE Statement.
Step1:
Inserting, Updating values from source table to identify and demonstrate use of OUTPUT Clause.
I have inserted two values with tagid 444, and 999.
I have updated value of tagid 505050.
I have deleted one row with tagid 101010.
in the result output we should be getting these three values in INSERTED and DELETED
Step2:
Execution of MERGE Statement.
the OUTPUT clause that I addes uses the “inserted” and “deleted” pseudo tables to displays the tagid’s for those rows that where inserted or deleted, as well as displays whether an INSERT, UPDATE, DELETE statement was done by reference the $action notation.
by reviewing the output, you can see that four different statements were executed. For each statement executed the tagid values for the inserted and deleted pseudo tables were displayed.
Only the UPDATE statement contains a tagid value in both inserted and deleted pseudo tables. These two values represent the before and after images of the tagid column when the UPDATE operation was performed.
————————————————————————————————————
TOP Clause In MERGE Statement
————————————————————————————————————
the MERGE Statement supports also a TOP clause. using the TOP clause on MERGE statement is just like using TOP clause on SELECT statement. when you used the TOP clause, SQL server will not more rows than the number supplied with the TOP clause.
for more information Please refer MSDN BOL.